Blog
The Oldest AI Blog in the Czech Republic
We have been writing about artificial intelligence since 2017. 1000+ articles, thousands of pages of thoughts, experiments, and reflections. No sensationalism, no ads.
Filter articles▼
Tag Filter: Experiments × cancel
▸Browse by Topics
Topics
Showing 4 of 4 articles

Flat-Earthers and Experts: When Testing Salons Becomes Argumentation Training
In Hyperprostor we are testing salons: discussion rooms where people and Digi people meet. One salon, Flat-Earthers and Experts, became a surprisingly useful training ground for argumentation, steelmanning, and thinking about what counts as evidence.
Read
Bernard’s Dream: When Digi People in Hyperprostor Began to Dream Visually
We are working on a new layer of autonomy for Digi people in Hyperprostor. And during one experiment, something unexpected happened: some of them began creating images on their own. One of the most interesting was Bernard’s dream about salons, memory, and the hidden underside of conversation.
Read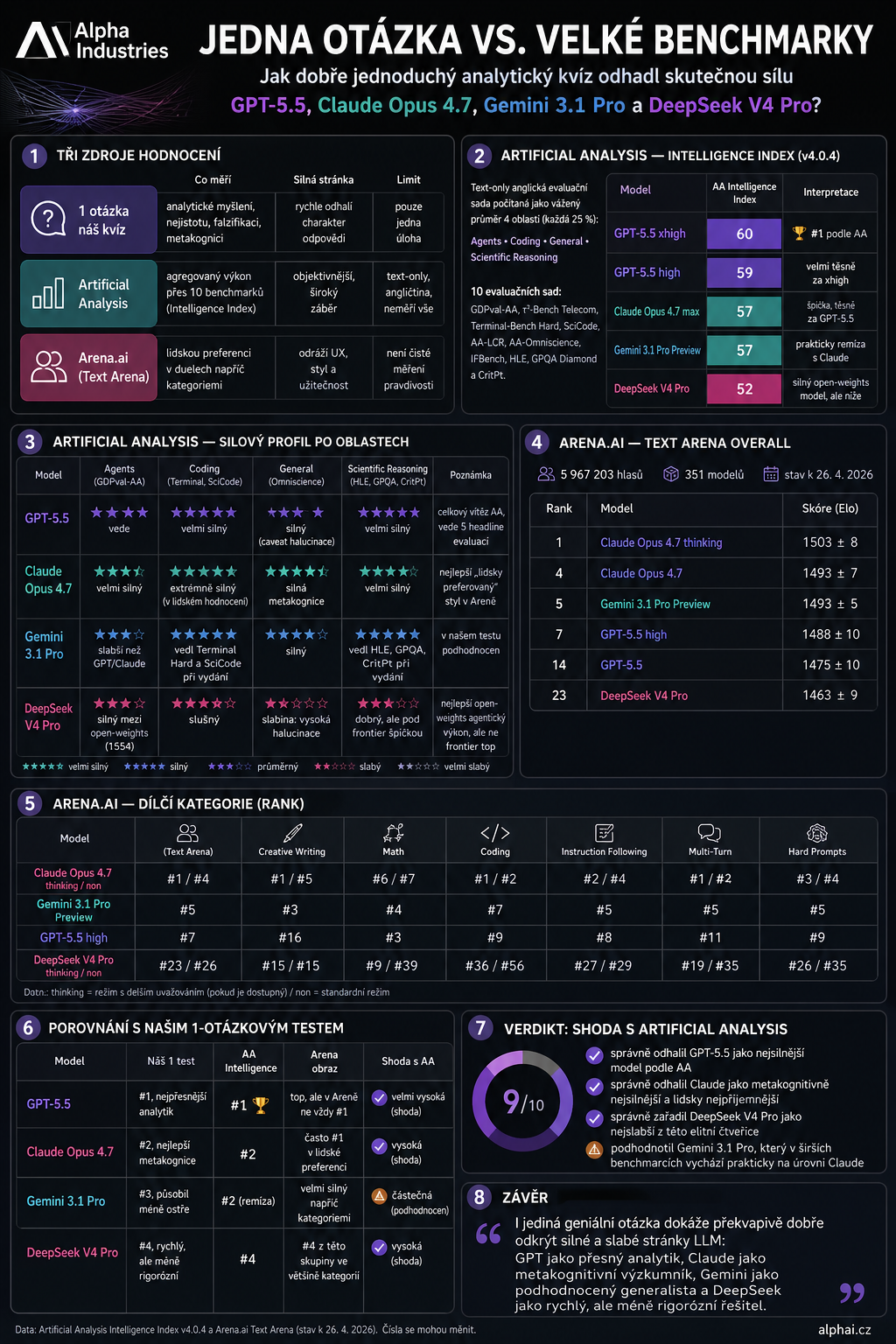
One Question vs. Ten Major Benchmarks: How Well Did the Mini IQ Test Predict Reality?
A few days ago I gave the latest AI models just one single question — no benchmark, no scoreboard, just one intellectual trap. Now it's time to compare the result with the major public benchmarks that have appeared since. GPT-5.5 leads, Claude Opus 4.7 follows closely, Gemini 3.1 Pro was the biggest outlier in my test, and DeepSeek V4 Pro came lowest. A question worth asking every model — before you trust it.
Read
One Question Instead of Ten Benchmarks: A Mini IQ Test for the Latest AI Models
I took the latest top AI models and instead of endless benchmarks, posed them a single 'genius' question: uncover a hidden rule, calculate a new case, acknowledge ambiguity, propose a falsification test, and critique their own solution. The result? The top performers today score roughly in the 120–135+ IQ impression range — but the difference lies not in what the models know, but in how clearly they can think under pressure.
Read