One Question vs. Ten Major Benchmarks: How Well Did the Mini IQ Test Predict Reality?
A few days ago I gave the latest AI models just one single question — no benchmark, no scoreboard, just one intellectual trap. Now it's time to compare the result with the major public benchmarks that have appeared since. GPT-5.5 leads, Claude Opus 4.7 follows closely, Gemini 3.1 Pro was the biggest outlier in my test, and DeepSeek V4 Pro came lowest. A question worth asking every model — before you trust it.
A few days ago I tried a small experiment: give the latest AI models just one single question.
Not a benchmark on hundreds of tasks. Not a scoreboard. Just one intellectual trap.
The model had to derive the rules of two artificial functions, mep and dap, calculate a new case, acknowledge ambiguity, propose the best test that could falsify its hypothesis, and state what it was least sure about.
The point was not to "measure IQ" in any psychological sense, nor to argue that classic benchmarks are useless.
If I could ask a model just one question — one that best reveals its analytical thinking, metacognition, and handling of uncertainty — what would it be?
The post was viewed by over 50 000 people, but judging by the comments, the point was missed by quite a few of them. After a few days, it's interesting to compare the result with the major public benchmarks that have appeared since.
📎 If you missed the original post, you can find it here: One Question Instead of Ten Benchmarks: A Mini IQ Test for the Latest AI Models
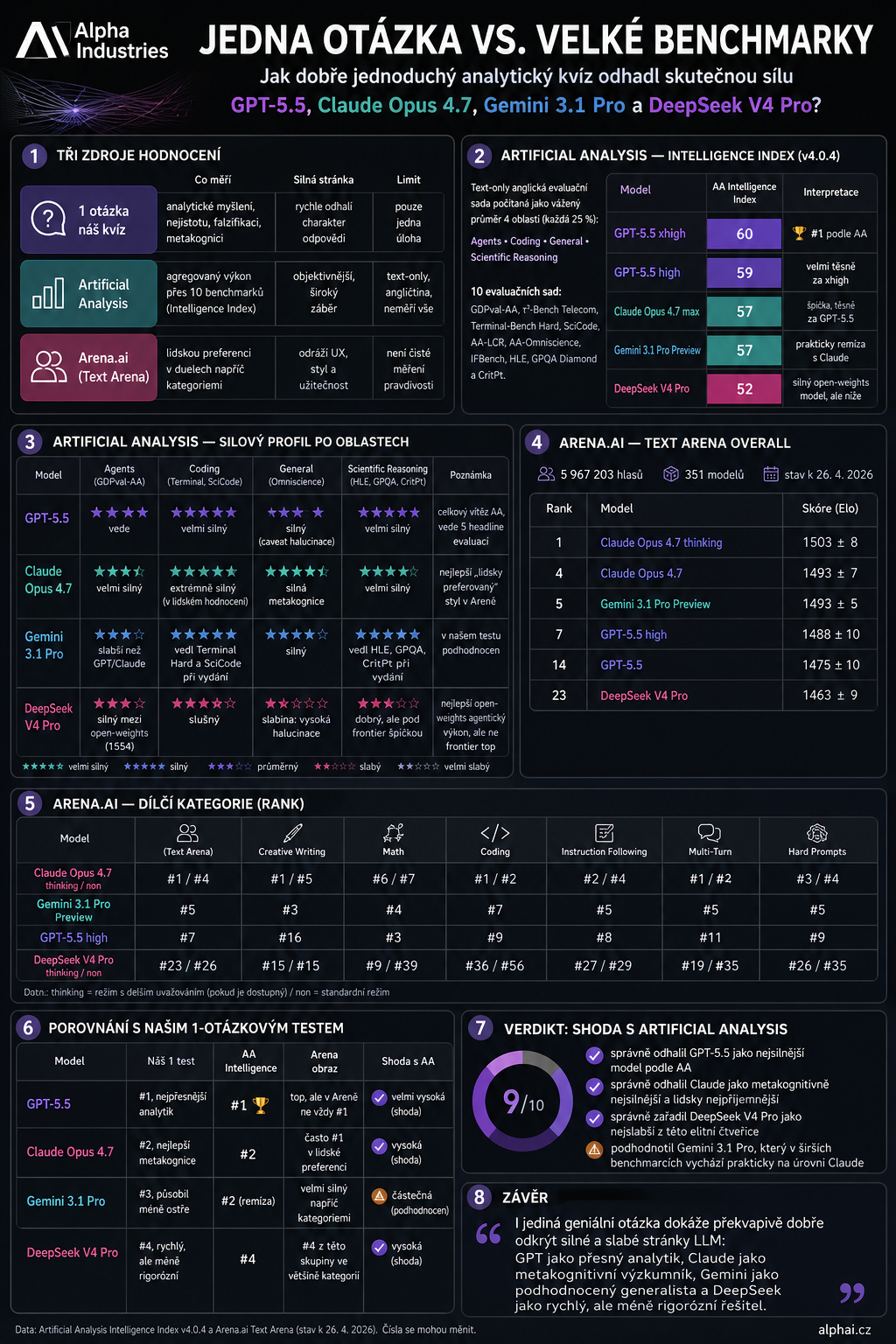
How Artificial Analysis Measures "Intelligence"
The Artificial Analysis Intelligence Index today computes a model's intelligence as a weighted average of four areas:
- Agents — 25 %
- Coding — 25 %
- General — 25 %
- Scientific Reasoning — 25 %
Together that's 10 evaluation suites: GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity's Last Exam, GPQA Diamond and CritPt.
Fair caveat: it's a text-only English evaluation set, so it doesn't measure everything — no Czech, no multimodality, no voice, no real-world UX usability.
So how did it turn out?
🥇 GPT-5.5 — the most confident analyst
GPT-5.5 is currently on top according to Artificial Analysis. GPT-5.5 xhigh has an Intelligence Index of 60, GPT-5.5 high of 59.
That fits well with my one-question test, where it came across as the most confident analyst: precise, compact, mathematically sharp.
🥈 Claude Opus 4.7 — researcher with metacognition
Claude Opus 4.7 sits at 57 on Artificial Analysis, just behind GPT-5.5. In human evaluations, however, it often goes higher — in Text Arena Overall, Claude Opus 4.7 thinking is actually first.
That's exactly the interesting difference: GPT acts like a very precise "mathematical sniper", while Claude behaves like a researcher with better metacognition, caution, and clearer articulation of uncertainty.
🥉 Gemini 3.1 Pro — the surprise of the broader benchmarks
Gemini 3.1 Pro was the biggest outlier in my one-question test. On that specific task it felt less sharp, prioritised the essentials a bit less, and worked less well with ambiguity.
But the wider benchmarks rate it much higher: Artificial Analysis gives it 57, putting it practically level with Claude Opus 4.7. In the Arena it is also very strong — in creative writing, mathematics, coding, and hard prompts it stays close to the top.
4. DeepSeek V4 Pro — strong, but not at the very top
DeepSeek V4 Pro came out as the lowest of these four in my test — fast, sharp, capable of pattern recognition, but less rigorous on accuracy, testing, and dealing with uncertainty.
The benchmarks confirmed this most strongly. Artificial Analysis gives it 52, below GPT-5.5, Claude, and Gemini. At the same time it's important to say that this is not a "stupid model" — on the contrary, it's a very strong open-weights model, just not at the very top of this elite group.
So how well did the one question hit the mark?
Surprisingly well, in my view.
The main thing it got wrong was how it underrated Gemini. But it nailed the main structure:
- GPT-5.5 and Claude are at the top.
- DeepSeek V4 Pro is the weakest of the four.
- The difference between models isn't just whether they get the right answer — it's whether they can acknowledge uncertainty, search for counter-examples, and not mistake an elegant guess for a proof.
And that was exactly the point.
I wasn't trying to build a "new benchmark". I was looking for a litmus test of intelligence: one question that forces the model to show not just calculation, but the way it thinks.
And the result was something quite encouraging:
A single well-designed question won't replace benchmarks. But it can reveal a model's character surprisingly well.
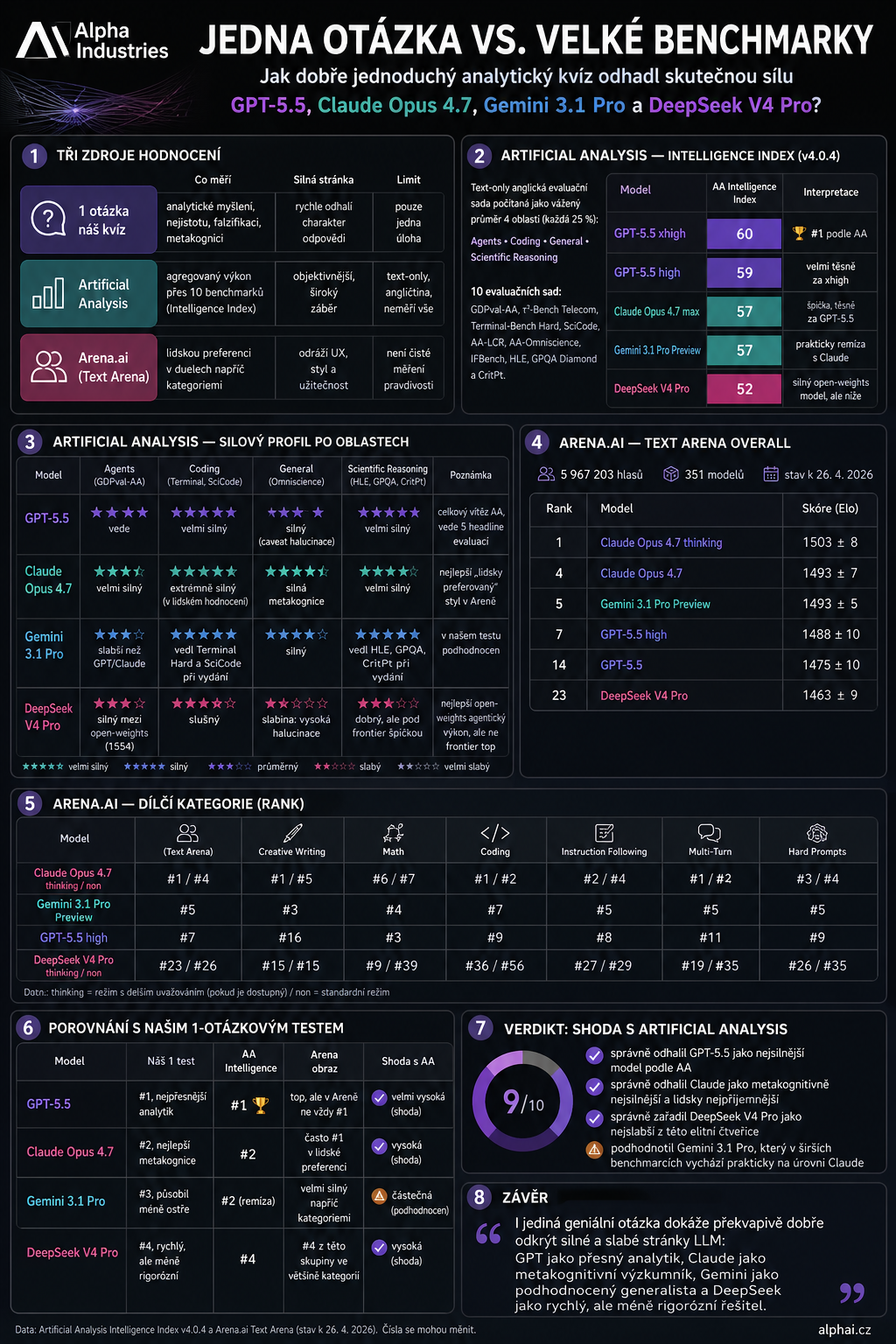
Detailed view — Intelligence Index as of 29 April 2026
Below you can see the models in fuller detail — a complete breakdown of the Intelligence Index across the major providers (as of 29 April 2026):
Which model is giving you the best results right now? Are you Team GPT, or Team Claude? Let me know in the comments!
#ArtificialIntelligence #LLM #ChatGPT #Claude #TechTrends #Alphai