Blog
The Oldest AI Blog in the Czech Republic
We have been writing about artificial intelligence since 2017. 1000+ articles, thousands of pages of thoughts, experiments, and reflections. No sensationalism, no ads.
Filter articles▼
Tag Filter: Claude Opus 4.7 × cancel
▸Browse by Topics
Topics
Showing 2 of 2 articles
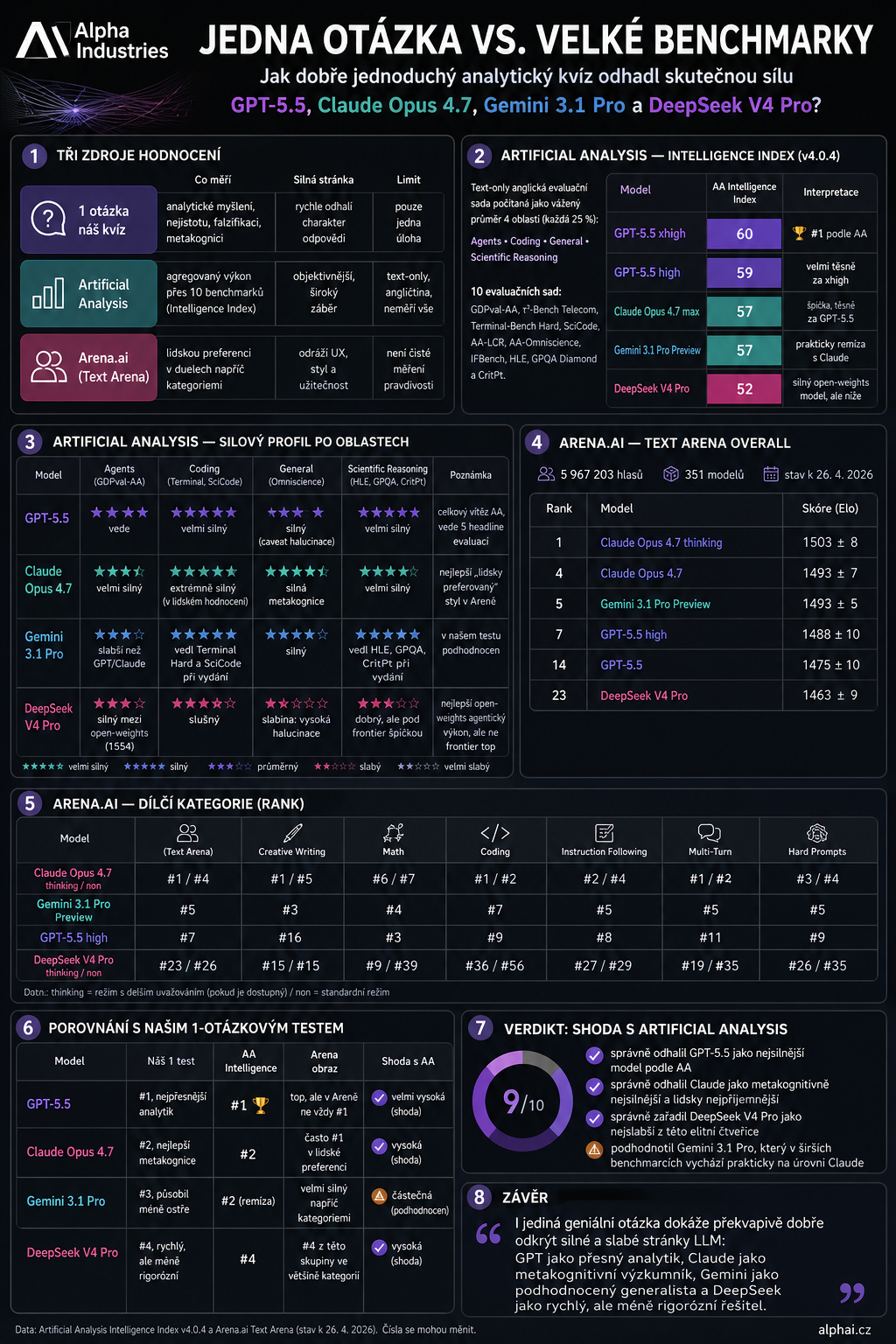
One Question vs. Ten Major Benchmarks: How Well Did the Mini IQ Test Predict Reality?
A few days ago I gave the latest AI models just one single question — no benchmark, no scoreboard, just one intellectual trap. Now it's time to compare the result with the major public benchmarks that have appeared since. GPT-5.5 leads, Claude Opus 4.7 follows closely, Gemini 3.1 Pro was the biggest outlier in my test, and DeepSeek V4 Pro came lowest. A question worth asking every model — before you trust it.
Read
One Question Instead of Ten Benchmarks: A Mini IQ Test for the Latest AI Models
I took the latest top AI models and instead of endless benchmarks, posed them a single 'genius' question: uncover a hidden rule, calculate a new case, acknowledge ambiguity, propose a falsification test, and critique their own solution. The result? The top performers today score roughly in the 120–135+ IQ impression range — but the difference lies not in what the models know, but in how clearly they can think under pressure.
Read