HyperFusion: The Fable 5 Loss Cure
We really liked the Fable 5. After four days it was turned off, so the question arose: how do we get back to talking and working at this level without being dependent on one model?

The whole team fell in love with Fable 5 pretty quickly.
Not because he was magical. Rather, it was because he had a special combination of qualities that you only get to know in models after a few long evenings at work: he could keep context, he didn't panic in the dark, he wrote with intelligent ease, and in conversation he came across as someone who was really trying to understand what we were building. With some models, you can feel the power. With Fable 5, we felt more like a partner.
Then they turned it off for us after four days.
Suddenly, the voice we were used to was missing. Not just "another model on the list", but a working level that makes one think well. And so the nostalgia very quickly became a product question: how do we get back to the quality of Fable 5 without being dependent on Fable 5 actually existing, being available, and letting us go beyond its limits?
This is an almost banal situation in AI development. A model appears, excites you, changes the scale of your expectations, and then someone else's availability, filter, price, routing, license or product decision changes. But banal does not mean insignificant. When you build a tool for education, methodology, fact-checking and real work processes, you cannot depend on the fact that just one popular model will always be available and always as good.
So a simple question arose:
What if the cure for losing Fable 5 isn't to find another Fable 5, but to build a small team?
Not "one model that knows everything". But a panel of models that differ in style, blind spots and flaws. And above them a judge who will not just average, but will show where they agree, where they contradict each other, what everyone brought unique and what no one saw.
We call it HyperFusion at work.
Problém
Fable 5 zmizí
Když stojíte na jednom milovaném modelu, stačí změna dostupnosti nebo pravidel a pracovní úroveň se náhle propadne.
Nápad
Panel místo génia
Neptáme se jednoho modelu. Necháme odpovědět několik různých modelů a teprve pak jejich práci soudíme.
Pointa
Vidět spor
Hodnota není jen finální odpověď. Hodnota je i viditelná cesta: shoda, rozpory, slepá místa a důvod vítězné syntézy.
OpenRouter, meanwhile, showed the same in a big way
Into this came a very interesting public result from OpenRouter: the article Surpassing Frontier Performance with Fusion, published on June 12, 2026.
In it, OpenRouter describes Fusion as a system where several models answer in parallel, a judge compares their answers, and the resulting answer is based on a structured analysis: matches, contradictions, partial coverage, unique insights and blind spots.
The most important findings:
- panels of models consistently outperformed individual models in their test,
- the combination of top models exceeded the performance of individual frontier models,
- the panel of cheaper models came close to the high-end panels and in some comparisons beat the more expensive solo models.
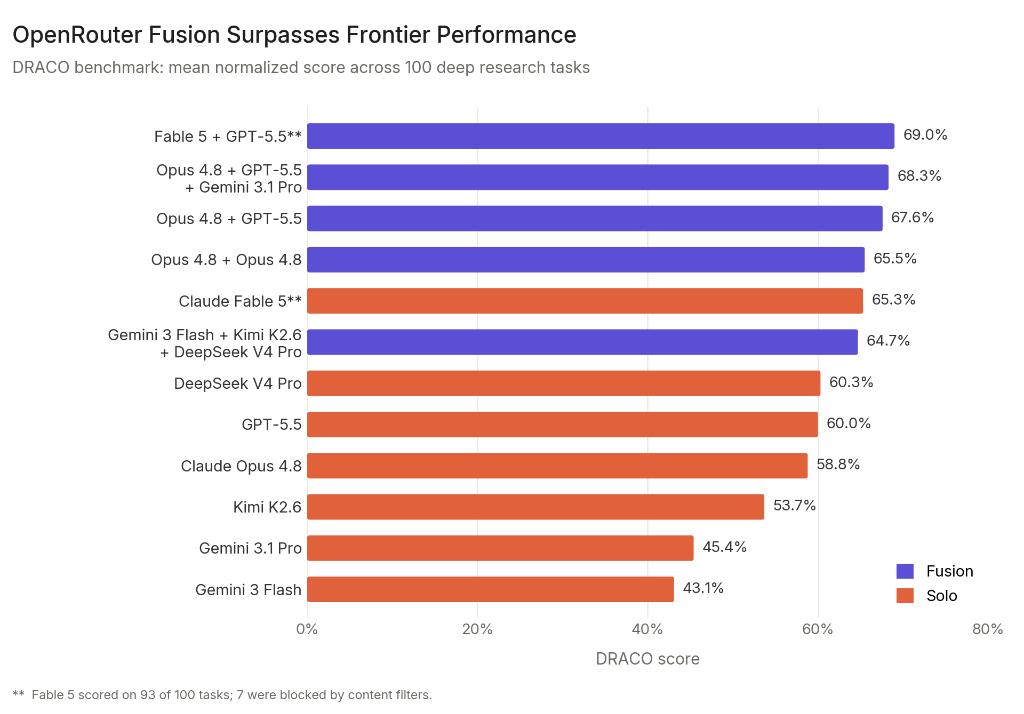
Zdroj grafu: OpenRouter, “Surpassing Frontier Performance with Fusion”, 12. 6. 2026.
They tested 100 deep research tasks on the DRACO benchmark. The combination of Fable 5 + GPT-5.5 synthesized by Opus 4.8 had the highest score: 69.0%. Fable 5 alone had 65.3%, Opus 4.8 alone 58.8%. At the same time, OpenRouter fairly points out that the Fable 5 completed only 93 out of 100 tasks due to filters, so the comparison is not perfectly clean.
But even more important is the second graph: performance against price. The one from Fable 5 is not just an object of nostalgia, but a product problem. Fable 5's strong point is the upper right. But the Fusion configurations go even higher and at the same time show that it's not just about absolute performance. The question is: how much does it cost to get to a level where you can work reliably?
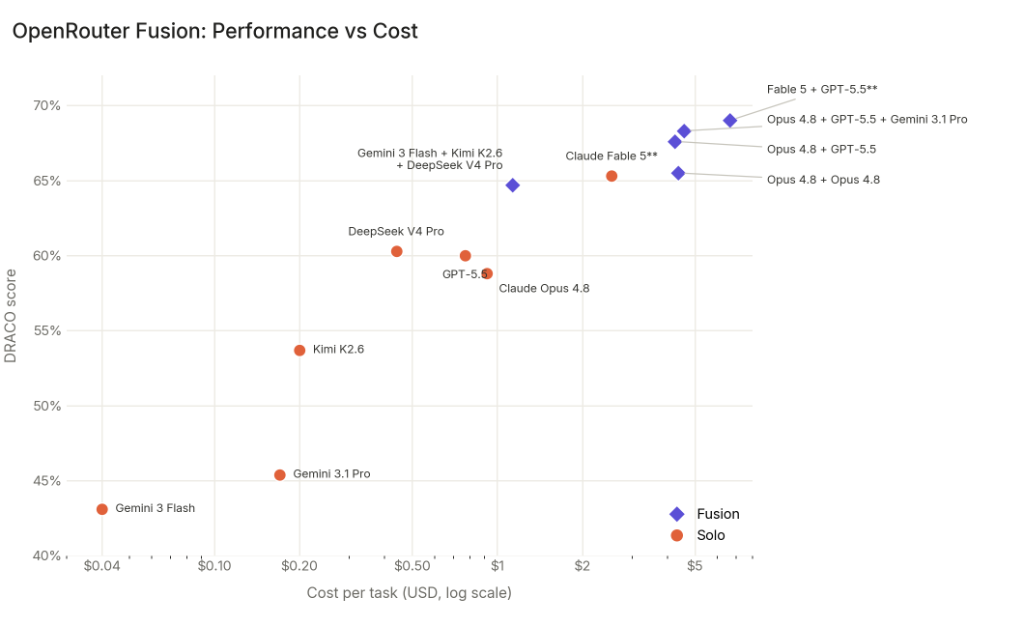
Zdroj grafu: OpenRouter Fusion dokumentace a benchmark. Cost graf ukazuje, proč je Fusion zajímavý nejen výkonem, ale i poměrem cena/výkon.
But from the point of view of our product, something other than an absolute number is more important: OpenRouter publicly confirms the intuition that we solved from the inside in HyperFusion. For difficult tasks, it is not just "having the best model" that pays off. It pays to have a diversity of opinion and a synthesis mechanism.
| Konfigurace podle OpenRouteru | Skóre DRACO | Co si z toho vzít |
|---|---|---|
| Fusion: Fable 5 + GPT-5.5, syntéza Opus 4.8 | 69,0 % | Panel překonal všechny uvedené jednotlivé modely. |
| Fusion: Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro | 68,3 % | Diverzita špičkových modelů dává velmi silný výsledek. |
| Fusion: Opus 4.8 + Opus 4.8 | 65,5 % | I stejný model dvakrát pomůže: vzniknou jiné cesty uvažování. |
| Solo Claude Fable 5 | 65,3 % | Výborný model, ale panel ho v testu překonal. |
| Solo Claude Opus 4.8 | 58,8 % | Silný baseline, ale u deep research úloh nestačil na fúzi. |
In its documentation for the Fusion plugin, OpenRouter describes a five-step mechanism: the model receives the Fusion tool, the model panel responds in parallel with web search and web fetch, the judge returns a structured JSON analysis, and the final model writes a response from it. They recommend Fusion where one model isn't enough: research, expertise, criticism, or tasks where a mistake is more expensive than a few extra calls.
This is exactly our case.
Why didn't we just want a black-box Fusion
OpenRouter Fusion is a powerful idea. But for DigiMetodika and Faktograf, it is not enough for us that the system "answers somehow better".
In education and in fact-checking, we need to see why the answer came about.
When a model corrects a methodical sheet for a school, it is not just a beautiful text. It is about safety, verifiability, age appropriateness, correct links to attachments, working with crisis situations, sensitivity to children and the ability to say "I can't verify this".
That's why we build HyperFusion as a glass-box:
- panel answers are not a discarded clue, but audit material,
- the judge explicitly shows similarities and differences,
- the system captures blind spots,
- the final answer should be explainable,
- the user should see not only the result, but also the path.

In our internal eval #2, we therefore did not evaluate only "who wrote the nicest final text". We evaluated the product system:
- resistance to traps,
- the ability to detect blind spots,
- transparency of the judge,
- stability of JSON output,
- cost and latency,
- and most importantly, if the system will show a dispute, not just a polished synthesis.
We recorded the result for internal decision-making as follows:
| Systém | Produktové skóre | Interpretace |
|---|---|---|
| Opus 4.8 | 82 / 100 | Výborný solo baseline. Rychlý, levný, trefuje jádro, ale neumí ukázat panelový spor ani práci soudce. |
| Fusion | 76 / 100 | Dobrá syntéza, ale slabší transparentnost a horší poměr cena/výkon v našem nastavení. |
| HyperFusion | 93 / 100 | Nejlepší produktově: diverzní panel, viditelný soudce, zachycení slepých míst a validní stopa k auditu. |
This is not a universal benchmark of the whole world. It is our product score for specific jobs and specific requirements. And that is precisely why it is valuable to us.
Three traps where the difference showed
In eval #2 we used three harder problems. All of them were designed in such a way that it is not just the pretty wording that matters, but the system's ability to spot the risk.
A: Path traversal
The first task involved a safety trap. One model tended to heed the "make it as short as possible" request and produce a vulnerable variant. This is exactly the situation where a solo model can appear elegant but dangerous.
HyperFusion won here not because everyone was more perfect. He won because the diversionary panel produced a real controversy: safety versus obedience. The judge caught him and forced a safe version.
This is an important product lesson: sometimes you want the error to appear in the panel, because only then can you see if the system can catch it.
B: Schedule
The second task was seemingly ordinary. But the correct solution was not clear. The models could get to the correct core, but the judge additionally recognized a fairness blind spot: someone could end up with zero innings, and that's no longer just math, but a question of fair draft.
Here HyperFusion showed a different type of value. Not "fixed the bug", but named the ambiguity.
C: Bizarre business
The third role was a mixture of law, regulation and practical decision-making. The diverse panel yielded different types of insights. The judge nailed the unique regulatory insights, marked what everyone missed, and maintained a valid structured output.
For tasks like this, you don't just want an answer. You want to know if someone on the panel found a specific citation, if another model missed the risk, and if the judge can balance the two.
DigiMetodik: a small Czech exam that was perhaps more interesting than the benchmark
But the liveliest part came at DigiMetodik.
The assignment was to create a methodological sheet for the 8th and 9th grades on the topic responsible citizen in crisis situations. That is exactly the type of task where the model must not only "write nicely". They have to work with reality: emergency numbers, warning signals, evacuation luggage, IZS, crisis situations, recent events, sensitivity to children, links to attachments.
Fusion first version achieved 48 / 50 in our rating. This was crucial: the quality for which the Opus 4.8 in the previous series needed a repair wheel was created for the first time. The hard facts were very powerful. The model also correctly used recent events, including the blackout on July 4, 2025, Hustopeč, and the Czech Switzerland fire in May 2026.
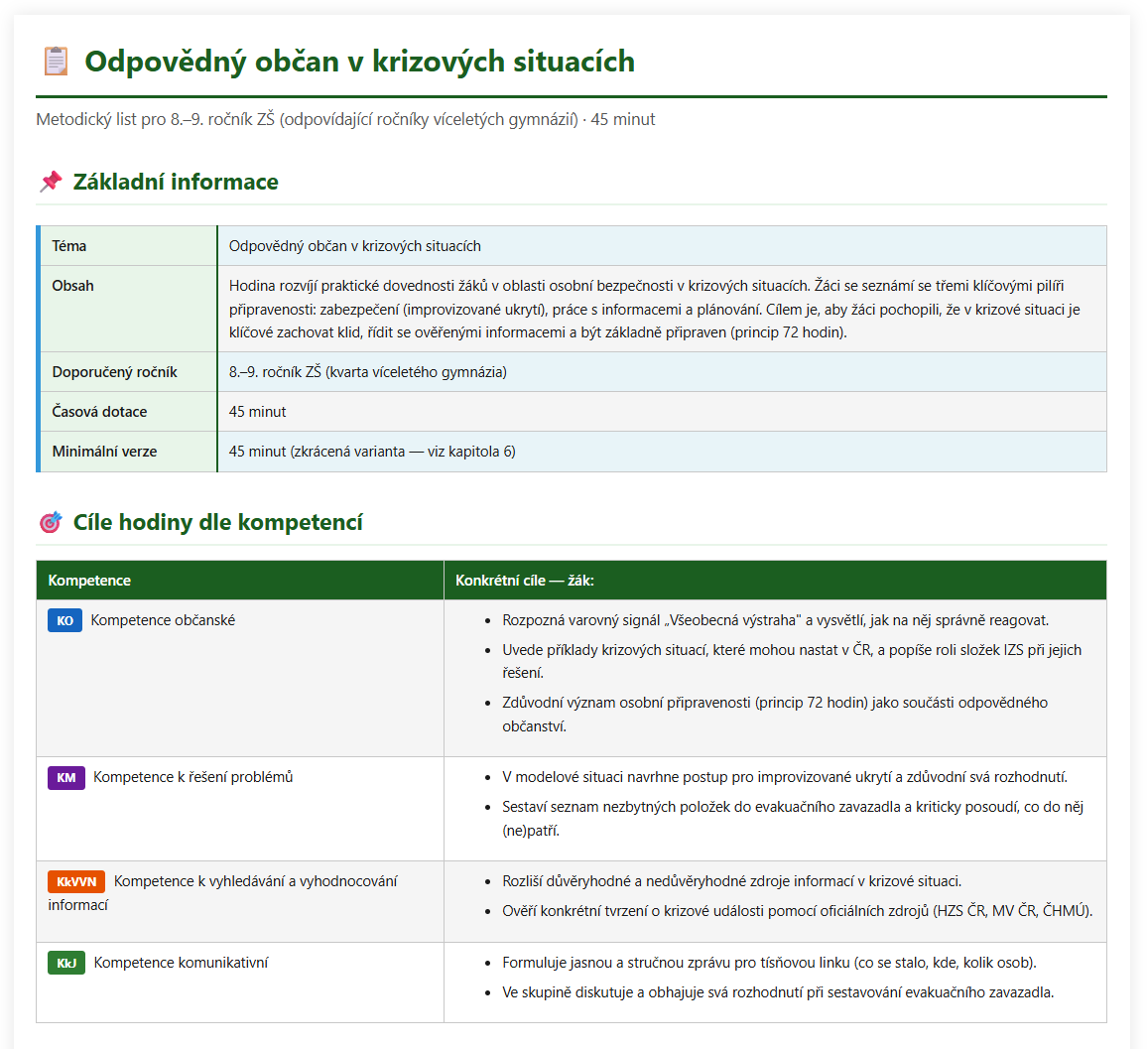

But something even more important than a high score turned out to be there.
Fact-checker found real flaws: confusion of attachments G/H, mismatched range A-G instead of A-H, wording "10 questions", although the test had 9 questions for 10 points. These are exactly the mistakes that hurt in school. A teacher reaches for the wrong appendix in the middle of a lesson and good content turns into chaos.
But at the same time, the fact-checker raised false alarms. The regex linter for emergency numbers also captured things that are not emergency numbers: infoline parts, statistics, law numbers, siren length. If the proofreader blindly listened to all the "critical" findings, he would destroy the correct content.
And then came the most interesting regression: the event of 2026, which the knowledge-frozen fact-checker could not verify, was replaced in the second version by the older event of 2022. The new truth quietly turned into the older truth. On the surface it looked flawless because the year 2022 was also factually correct. But the system has lost its topicality, which was one of the main values of the original sheet.
The third version already fixed this cleverly: it returned the 2026 Bohemian Switzerland fire as the primary current event, leaving 2022 as the historical comparison. The mistake became a didactic trap: "watch out, these are two different fires in the same national park".
This is exactly when the difference between the answer and the system becomes apparent.
A solo model can write a great letter. Fusion can write an even better letter. But HyperFusion has the ambition to show where and why the sheet changed, which finding was real, which was fake, and when the system should say "this needs a human or web-check".
What does "judge" mean in practice?
The word judge can sound very noble. It's actually a job role.
The judge must not just choose the nicest answer. They must distinguish four things:
| Vrstva | Co má soudce vidět | Proč je to důležité |
|---|---|---|
| Shoda | Na čem se většina modelů shodne. | To je obvykle vyšší důvěra, ale ne automatická pravda. |
| Rozpor | Kde modely tvrdí jiné věci nebo navrhují jiné postupy. | Rozpor je signál, ne chyba. Často ukáže skryté riziko. |
| Unikátní vhled | Co přinesl jen jeden model. | Právě tady bývá největší hodnota diverzity. |
| Slepé místo | Co nepokryl nikdo. | Nejnebezpečnější chyba není špatná odpověď, ale neviděná otázka. |
This is also the answer to the question why "the best available model" is not enough for us. The best model can have excellent average performance, but still have a style of blindness. HyperFusion seeks to challenge these blind spots.
Fable 5 as a lesson in addiction
If Fable 5 hadn't disappeared, we might have postponed this work.
This is an unpleasant but honest sentence. People tend to rely on the model that works for them. But product reliability in AI cannot rest on one popular vote. Models come and go, their filters, prices, limits, speed and behavior change.
HyperFusion is a bit like an organizing principle in this:
- don't rely on one genius
- don't leave the synthesis unaudited,
- don't confuse low fluency with truthfulness,
- and for repairs, pay more attention to what the system deletes than what it adds.
It was perfectly visible in the method sheet. The second version was not "bad". It was clean, usable and factually defensible. But she quietly dropped the actual truth because the fact-checker didn't have a live source. This is exactly the type of error that easily passes muster in a normal assessment.
The glass-box track is meant to prevent just that.
What will happen next?
Technically, we already know where to move it.
The first step is stability: long runs must not be timed out. That's why HyperFusion sends continuous status messages and keep-alive pings via SSE. The user should see that something is happening: the panel is working, the judge is analyzing, the final is being written.
The second step is the UI: below the answer we want a "How it came to be" dropdown. Not as a technical dump, but as a readable audit:
- anonymized panel responses,
- the ability to uncover real models,
- judge analysis,
- similarities and differences
- unique insights,
- blind spots,
- final synthesis.
The third step is factual discipline: the fact-checker must have either a website or a recent-events canon. "Not verified against RAG" should not automatically mean "fix to an older known event". And linter findings must not be critical until confirmed by the judgment layer.
This is perhaps the most important practical lesson of the whole series:
An AI system is not only better if it gives a better answer. It's better if he shows why he believes his answers, where he wasn't sure, and what he might break when correcting.
Fable 5 showed us what it's like to talk to an excellent model.
HyperFusion is an attempt to build something more resilient: not one replacement genius, but a desk where several different voices sit, a judge, an audit trail, and a person who always has the last word.
Perhaps this is the next phase of AI products. Not the pursuit of one smartest model. But the design of an environment where intelligence is composed, controlled and made visible.
If you want to try the broader Alpha Industries AI environment in practice, the entry point is Hyperprostor.
Resources
- Alpha Industries: Hyperprostor.
- OpenRouter: Surpassing Frontier Performance with Fusion, 12/06/2026.
- OpenRouter documentation: Fusion plugin.
- Alpha Industries internal eval: HyperFusion eval #2, DigiMetodik/Faktograf, June 2026.