HyperAdvisor a HyperFusion Deep: turbo boost pro AI i nová vrstva reasoning systému
Co kdyby AI fungovala jako procesor v notebooku: většinu času levně a rychle, ale u těžkých úloh sama zařadila vyšší rychlost? A co když pro nejtěžší kognitivní otázky nestačí lepší model, ale celý orchestr expertů?

Před osmi lety mě napadla jednoduchá myšlenka. Každý počítač, který používáte, ji dělá pořád: procesor neběží celou dobu naplno. Když píšete e-mail, jede na nízké frekvenci a skoro nežere. Když spustíte render, hru nebo kompilaci, zařadí vyšší rychlost. Intel tomu říkal Turbo Boost, obecně jde o dynamické škálování výkonu.
Plný výkon dostanete jen ve chvíli, kdy ho opravdu potřebujete.
A přesně tohle dlouho chybělo umělé inteligenci.
Problém: nejsilnější model většinou nepotřebujete
Špičkové modely jsou úžasné, ale drahé. A tady je praktický háček: většina dotazů žádnou frontier inteligenci nepotřebuje. „Kolik je 6 + 3?“ nebo „shrň mi tenhle odstavec“ zvládne levný a rychlý model za zlomek ceny.
Jenže když nastavíte bota na nejsilnější model, platíte nejvyšší sazbu za každou zprávu, i za triviální otázku. Je to podobné, jako kdyby procesor v notebooku běžel pořád na maximum, i když jen čtete poštu.
Proto jsme postavili HyperAdvisor.
HyperAdvisor: turbo boost pro AI
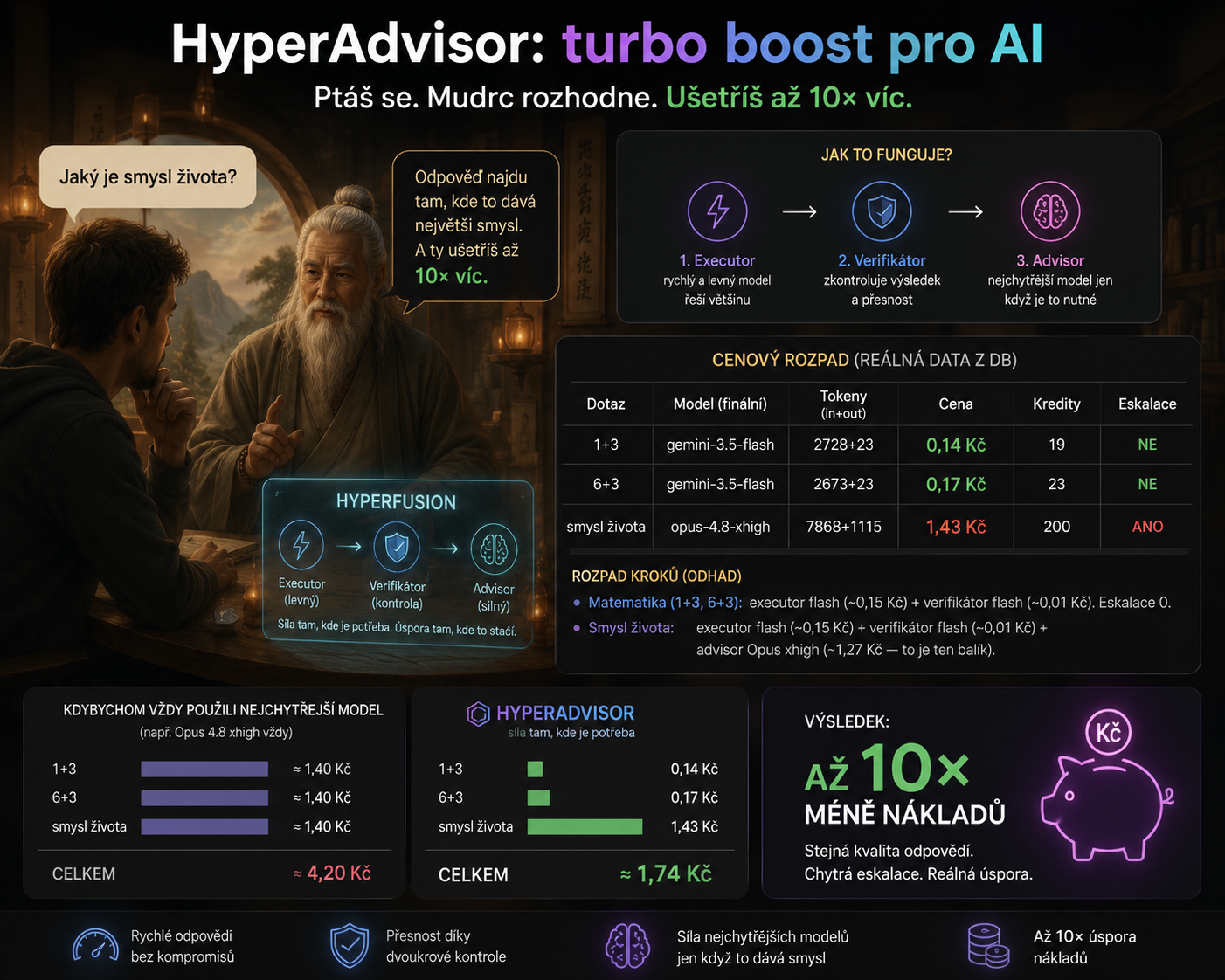
HyperAdvisor funguje jako chytrý mudrc u brány: většinu dotazů nechá vyřešit levně, ale když je otázka těžká, pustí dovnitř nejsilnější model.
HyperAdvisor funguje ve třech krocích:
- Levný a rychlý model odpoví jako první.
- Druhý levný model jeho odpověď nezávisle zkontroluje.
- Jen když kontrola najde pochybnost, systém eskaluje na nejsilnější model.
Pointa je ve druhém kroku. Existují řešení, kde se slabší model má sám rozhodnout, že na něco nestačí. Jenže slabší model často neví, že neví. HyperAdvisor proto používá nezávislého verifikátora. Ten může zachytit, že levný model odpověděl sebevědomě, ale špatně, a teprve pak pustí do hry těžkou váhu.
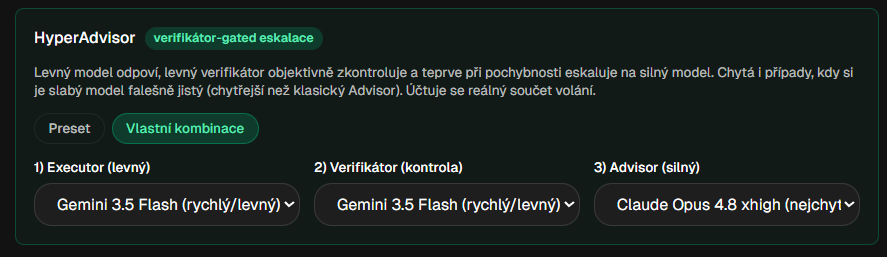
HyperAdvisor: levný model odpoví, levný verifikátor zkontroluje a jen při pochybnosti eskaluje na silný model.
Na jednoduchých dotazech to znamená dramatickou úsporu. V našem testu Mistra Yody stály jednoduché otázky typu „kolik je 1 + 3?“ nebo „kolik je 6 + 3?“ kolem desetin koruny. Těžší otázka „jaký je smysl života?“ se eskalovala na nejsilnější model a stála zhruba řádově víc, ale přesně tam to dávalo smysl.
Nešetříme tím, že bychom dělali méně práce. Šetříme tím, že běžný provoz jede na nižší „frekvenci“ a plný výkon se zapíná jen u úloh, které ho opravdu potřebují.
Kolik to stojí v praxi
Největší rozdíl je vidět na jednoduché aritmetice. Kdybychom vždy použili nejsilnější model, každá zpráva by stála přibližně stejně, bez ohledu na obtížnost. HyperAdvisor ale pustí drahý model jen tehdy, když verifikátor najde důvod k eskalaci.
| Dotaz | Finální model | Cena HyperAdvisoru | Kdyby jel vždy nejsilnější model | Úspora | Eskalace |
|---|---|---|---|---|---|
| 1 + 3 | Gemini 3.5 Flash | 0,14 Kč | cca 1,40 Kč | až 10× levněji | ne |
| 6 + 3 | Gemini 3.5 Flash | 0,17 Kč | cca 1,40 Kč | zhruba 8× levněji | ne |
| Jaký je smysl života? | Claude Opus 4.8 xhigh | 1,43 Kč | cca 1,40 Kč | nešetří, používá sílu tam, kde dává smysl | ano |
V tom je pointa: člověk nemusí volit mezi „levné, ale hloupější“ a „chytré, ale drahé“. Může mít obojí. HyperAdvisor používá nejchytřejší model jako vzácný zdroj: ne na každou banalitu, ale přesně tam, kde levný model narazí nebo kde otázka vyžaduje hloubku.
V malém testu by tři dotazy stály při trvalém použití nejsilnějšího modelu asi 4,20 Kč. HyperAdvisor je zvládl za přibližně 1,74 Kč. A u provozu, kde většina dotazů bývá jednoduchá, se úspora může blížit až desetinásobku.
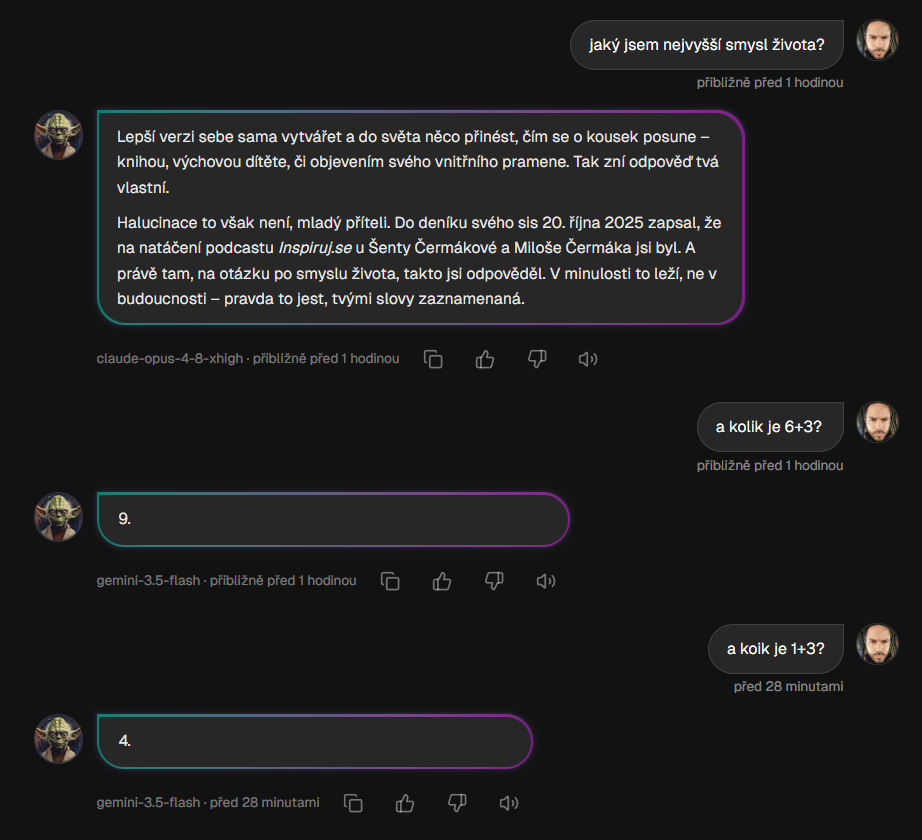
V chatu je vidět praktický rozdíl: jednoduchý výpočet nevyžaduje nejdražší model, zatímco otevřená otázka může spustit silnější vrstvu.
A pak je tu druhý extrém: HyperFusion Deep
HyperAdvisor řeší ekonomiku běžného provozu. Jenže o víkendu jsem dotáhl ještě druhou věc: HyperFusion Deep.
To už není jen chytré přepínání mezi levným a drahým modelem. Je to jiná třída systému. Neřeší otázku „kdy pustit silnější model“, ale „jak složit několik expertů tak, aby vzniklo lepší myšlení než u jednotlivého modelu“.
U předchozích testů DRACO jsme HyperFusion používali hlavně na náročné znalostní a rešeršní úlohy. Psali jsme o tom v článku HyperFusion po opravách: DRACO benchmark a cesta k expertní porotě AI. Tam se ukázalo, že panel modelů, soudce a dobrá syntéza dokážou porazit samotný silný model hlavně tím, že pokryjí víc zdrojů, citací a slepých míst.
HyperFusion Deep jde dál. Testoval jsem ho i na náročných kognitivních úlohách, které nejsou jen o dohledání znalostí. Vyžadují abstrakci, logiku, metakognici, kontrolu důkazů, schopnost odmítnout slabý test a argumentovat proti vlastnímu závěru.
To je přesně typ úloh, který jsem dlouhodobě sledoval už v článku Jedna otázka vs. velké benchmarky. Jedna dobře zvolená otázka někdy ukáže víc než tabulka plná průměrů, protože prověří kvalitu myšlení, ne jen šířku encyklopedie.
Ne lepší model. Vyšší vrstva systému
Tady je důležité být marketingově poctivý. Kdybych HyperFusion Deep dal jen do běžného žebříčku vedle solo modelů, vypadalo by to jako malý rozdíl:
Silný solo model
8.7
Jeden velmi silný model, ale pořád jedna perspektiva a jedna sada slepých míst.
Fusion / HyperFusion
9.2
Více modelů, lepší pokrytí, silnější syntéza a kontrola rozporů.
HyperFusion Deep
9.4
Ne jen vyšší skóre, ale jiný způsob řešení: orchestr, soudce, syntéza a metakritika.
Na první pohled by někdo řekl: rozdíl jen 0,2 bodu.
Jenže to není pointa. Pointa není, že HyperFusion Deep je o pár procent lepší model. Pointa je, že to není model. Je to systémová AI: tým expertů, soudce, analytik slepých míst, syntetizér a vrstva sebekorekce.
Je to podobné, jako kdybyste srovnávali jednoho šachového velmistra s týmem velmistrů, trenérem a analytikem příprav. Nejde jen o to, kdo má o něco vyšší Elo. Jde o jiný způsob práce.

HyperFusion Deep není v grafice jen první řádek tabulky. Je oddělený jako systémová vrstva: orchestr expertů, judge, blind spot analýza, sebekorekce a meta-reasoning.
Ještě marketingověji řečeno: HyperFusion Deep je jedna kombinace modelů, která se v našem testu dotýká IQ-dojmu kolem 140. Ten převod na lidské IQ je samozřejmě silně zjednodušený a nemá se číst jako psychometrické měření člověka. Ale pro intuitivní popis síly reasoning systému je užitečný: ukazuje, že se nedíváme jen na rychlejší encyklopedii, ale na vrstvu, která začíná působit opravdu mimořádně chytře.
AI je pořád zvláštní. Někdy je zubatá, někdy udělá banální chybu, někdy potřebuje dohled a dobré mantinely. Ale právě v téhle zubatosti se začíná objevovat něco důležitého: když ji donutíte ověřovat, oponovat si, skládat různé pohledy a přiznávat nejistotu, její inteligence skutečně roste. Ne jako kouzelný člověk v počítači. Spíš jako nový typ kognitivního stroje, který při správné orchestraci začíná být až geniální.
Co ostatní modely typicky neumí
Solo model, i když je velmi silný, pořád odpovídá z jedné perspektivy. Fusion přidává více hlasů. HyperFusion přidává průhlednější soudcovství a syntézu. HyperFusion Deep se snaží přidat ještě hlubší práci s důkazy a limity vlastního závěru.
| Schopnost | Solo modely | Fusion | HyperFusion | HyperFusion Deep |
|---|---|---|---|---|
| Více nezávislých expertů | ne | ano | ano | ano |
| Judge vrstva | ne | částečně | ano | ano |
| Blind spot analýza | ne | omezeně | ano | ano |
| Sebekorekce syntézy | ne | částečně | ano | ano |
| Meta-kritika důkazů | ne | částečně | ano | ano |
| Argument proti vlastnímu závěru | ne | ne | ano | ano |
| Orchestrace specialistů | ne | omezeně | ano | silná |
Proto bych HyperFusion Deep nedával do běžného pořadí modelů 1 až 8. Dává větší smysl rozlišit dvě kategorie:
- Solo modely: Opus, GPT, Gemini, DeepSeek a další jednotlivé modely.
- Multi-agent systémy: Fusion, HyperFusion a HyperFusion Deep.
A pak nad tím říct: HyperFusion Deep je prototyp vyšší vrstvy. Ne proto, že by měl o pár desetinek lepší skóre, ale proto, že umí lépe organizovat samotné myšlení.
Dvě úrovně praktické AI
Když si to celé spojím, vznikají dvě vrstvy.
První vrstva je HyperAdvisor: běžný provoz levně a rychle, plný výkon jen při pochybnosti. To je ekonomika. Bez ní nejde AI škálovat ve firmách, školách ani každodenních produktech.
Druhá vrstva je HyperFusion Deep: když už otázka není jen „najdi odpověď“, ale „promysli problém, zvaž důkazy, najdi slabá místa, oponuj si a slož robustní závěr“. To je kvalita reasoning systému.
Obě vrstvy míří ke stejné věci: AI nemá být jen jeden drahý model, který použijeme na všechno. Má to být inteligentní architektura, která ví, kdy šetřit, kdy eskalovat a kdy zapojit celý orchestr.
Co dál
Tohle jsou zatím naše interní testy a produktové experimenty. Neberu je jako definitivní akademický benchmark. U podobných úloh vždy záleží na zadání, hodnoticí metodice, výběru modelů i opakování běhů.
Ale jako směr mi to přijde velmi silné.
Budoucnost praktické AI podle mě nebude jeden univerzální model nastavený na všechno. Bude to kombinace:
- levných modelů pro běžný provoz,
- verifikátorů, kteří hlídají chyby,
- silných modelů pro eskalaci,
- panelů expertů pro náročné úlohy,
- soudců a syntetizérů,
- a metakognitivních vrstev, které kontrolují, jestli systém sám sobě příliš nevěří.
To je rozdíl mezi chatbotem a pracovním kognitivním systémem.
HyperAdvisor je turbo boost pro AI. HyperFusion Deep je krok k orchestraci myšlení.
Zdroje a další čtení
- Alpha Industries: Jedna otázka vs. velké benchmarky.
- Alpha Industries: HyperFusion po opravách: DRACO benchmark.
- Alpha Industries: HyperFusion: když jeden model nestačí.
- Hyperprostor: vyzkoušet práci s boty a modely.
Poznámka k poctivosti: skóre a „IQ-dojem“ v článku beru jako interní kvalitativní srovnání konkrétního typu úloh, ne jako univerzální měření inteligence. Pointa článku není absolutní číslo, ale rozdíl mezi jedním modelem a systémem, který umí orchestraci, kontrolu a syntézu.